項(xiàng)目的技術(shù)路線及預(yù)期成果
技術(shù)路線:
整體項(xiàng)目采用微服務(wù)理念,根據(jù)業(yè)務(wù)縱向分割�����,獨(dú)立成服務(wù)��。服務(wù)之間互相獨(dú)立��,降低局部故障對(duì)整體系統(tǒng)的影響,提高系統(tǒng)的容災(zāi)性以及穩(wěn)定性����。每個(gè)服務(wù)采用Spring、Spring MVC�、Spring Boot���、MyBatis結(jié)構(gòu)構(gòu)建�����。
系統(tǒng)架構(gòu)圖如下:
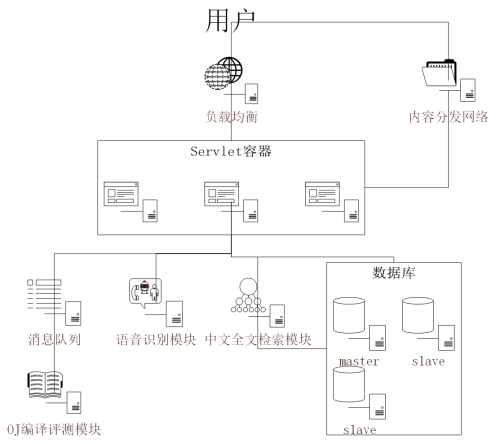
負(fù)載均衡:
采用Nginx作為負(fù)載均衡模塊,輕量高效,可以和后端的應(yīng)用服務(wù)協(xié)調(diào)的契合。將用戶請(qǐng)求分散給后端服務(wù)�,降低單機(jī)負(fù)載����。
內(nèi)容分發(fā)網(wǎng)絡(luò):
將靜態(tài)內(nèi)容(例如用戶頭像)緩存至CDN服務(wù)器���,提高用戶訪問(wèn)速度�,降低服務(wù)器負(fù)載。
消息隊(duì)列:
采用ActiveMQ作為消息隊(duì)列模塊,將并行請(qǐng)求轉(zhuǎn)化為串行請(qǐng)求���,削峰填谷�,保證OJ服務(wù)器負(fù)載平穩(wěn),運(yùn)行穩(wěn)定����。
OJ編譯評(píng)測(cè)模塊:
OJ編譯評(píng)測(cè)模塊需要重點(diǎn)處理的問(wèn)題就是安全問(wèn)題����,由于需要將用戶輸入源碼編譯并運(yùn)行��,這個(gè)過(guò)程中存在較大的安全隱患���。我們將對(duì)外部輸入代碼進(jìn)行白名單驗(yàn)證,并利用Linux系統(tǒng)下成熟的沙箱技術(shù)Apparmor對(duì)運(yùn)行期的評(píng)測(cè)程序做細(xì)粒度的權(quán)限控制。保證被評(píng)測(cè)程序的運(yùn)行不影響服務(wù)器的安全穩(wěn)定。
語(yǔ)音識(shí)別模塊:
語(yǔ)音識(shí)別模塊用于解析用戶聲音��,轉(zhuǎn)化為文字再對(duì)文檔進(jìn)行搜索���。由于語(yǔ)音識(shí)別技術(shù)過(guò)于復(fù)雜,我們將調(diào)用現(xiàn)有的成熟技術(shù)解決方案以實(shí)現(xiàn)對(duì)音頻的解析�����。語(yǔ)音識(shí)別的基本原理如下:
1�����、發(fā)出的語(yǔ)音屬于模擬信號(hào)�����,為了對(duì)語(yǔ)音信號(hào)進(jìn)行分析和處理��,需要進(jìn)行模數(shù)轉(zhuǎn)換
2����、數(shù)字化后��,提取語(yǔ)音信號(hào)的聲學(xué)特征:
1)人耳的生理特性:
生理 感知
強(qiáng)度 響度
基本頻率 基音
頻譜形狀 音色
開(kāi)合時(shí)間 時(shí)間
雙耳相位差 位置
2)根據(jù)人耳的生理特征進(jìn)行聲學(xué)特征提取:把每一幀波形變成一個(gè)多維向量�����,可以理解為這個(gè)向量包含了這幀語(yǔ)音的內(nèi)容信息����。
3�、得出語(yǔ)音識(shí)別結(jié)果
1)把幀識(shí)別成狀態(tài)
通過(guò)“聲學(xué)模型”里的參數(shù)�����,獲取幀和某一狀態(tài)對(duì)應(yīng)的概率����,若干幀數(shù)對(duì)應(yīng)一個(gè) 狀態(tài)。
2)把狀態(tài)組合成音素�。
每三個(gè)狀態(tài)組成一個(gè)音素���。
3)把音素組合成單詞。
中文全文檢索模塊:
1)中文分詞
高效準(zhǔn)確的中文分詞算法是搜索引擎實(shí)現(xiàn)的第一步����,本程序采用基于CRF算法的中文分詞實(shí)現(xiàn)。
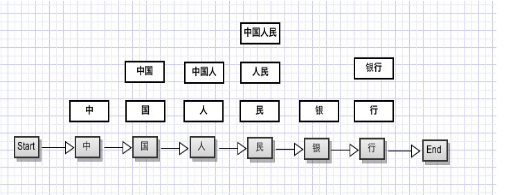
首先對(duì)每一個(gè)字計(jì)算出一個(gè)標(biāo)簽屬性��,某個(gè)字根據(jù)CRF模型提供的模板生成了一系列特征函數(shù),這些函數(shù)的輸出值乘以該函數(shù)的權(quán)值最后求和得出了一個(gè)分?jǐn)?shù)�。該分?jǐn)?shù)只是“點(diǎn)函數(shù)”的得分,還需加上“邊函數(shù)”的得分。邊函數(shù)在本分詞模型中簡(jiǎn)化為f(s',s),其中s'為前一個(gè)字的標(biāo)簽���,s為當(dāng)前字的標(biāo)簽。于是該邊函數(shù)就可以用一個(gè)4*4的矩陣描述,相當(dāng)于HMM中的轉(zhuǎn)移概率。然后通過(guò)BEMS合并����,將分詞結(jié)果送入詞性數(shù)據(jù)庫(kù)中查詢?cè)~性�,去除停詞(Stop word)后進(jìn)行下一步反向索引����。
2) 反向索引的建立
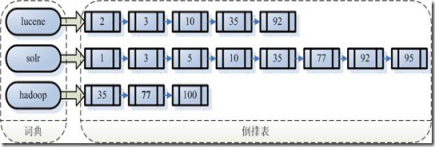
將分詞后得到的詞建立一個(gè)字典,按自然順序排序�,合并相同的詞�����,成為文檔倒排鏈表�����。便于搜索引擎根據(jù)關(guān)鍵字快速查詢文章。
3) 索引索引
對(duì)用戶輸入的查詢語(yǔ)句進(jìn)行自然語(yǔ)言分析,識(shí)別單詞關(guān)鍵字(此處和中文分詞基本相同)形成自然語(yǔ)言語(yǔ)法樹(shù)�,根據(jù)關(guān)鍵詞在反向索引表中查詢文檔����。
4) 整合結(jié)果文檔
根據(jù)自然語(yǔ)言語(yǔ)法樹(shù)對(duì)查詢到的文檔進(jìn)行合并、差等操作。通過(guò)關(guān)鍵詞詞頻等參數(shù)計(jì)算文檔相關(guān)度���,并排序顯示給用戶�����。
數(shù)據(jù)庫(kù)服務(wù)器:
關(guān)系型數(shù)據(jù)庫(kù)服務(wù)器將采用MySQL Server�,NoSQL服務(wù)器將采用Redis�。我們將用戶狀態(tài)信息(例如session)儲(chǔ)存在Redis中��,保證應(yīng)用服務(wù)器無(wú)狀態(tài)性�����,易于平滑擴(kuò)展�����。
應(yīng)用結(jié)構(gòu)層次如下:
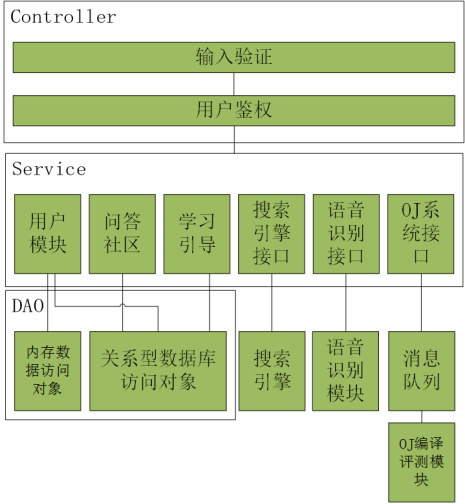
我們將應(yīng)用進(jìn)行橫向拆分�����,形成Controller���,Service,DAO結(jié)構(gòu)��。
Controller層負(fù)責(zé)與用戶交互收發(fā)信息�,驗(yàn)證輸入數(shù)據(jù)合法性�����,按照一定規(guī)則將請(qǐng)求分發(fā)給Service����。Service層拆分處理請(qǐng)求���。DAO層負(fù)責(zé)與數(shù)據(jù)庫(kù)交互��。我們采用微服務(wù)理念�����,將復(fù)雜而邏輯依賴少的模塊(例如搜索引擎�、語(yǔ)音識(shí)別���、OJ測(cè)評(píng))獨(dú)立出來(lái)����,以微服務(wù)的形式存在��,服務(wù)與服務(wù)之間采用RPC協(xié)議通訊,每個(gè)服務(wù)專人負(fù)責(zé)�,保證系統(tǒng)穩(wěn)定性����,降低單服務(wù)復(fù)雜度�����。
預(yù)期成果:
1�����、完成《基于java web 完成智能化編程語(yǔ)言初學(xué)者導(dǎo)引平臺(tái)系統(tǒng)》軟件設(shè)計(jì)。
2����、對(duì)整個(gè)項(xiàng)目過(guò)程進(jìn)行總結(jié)�����,做一份項(xiàng)目報(bào)告����。
3、申請(qǐng)軟件著作權(quán)���。
|